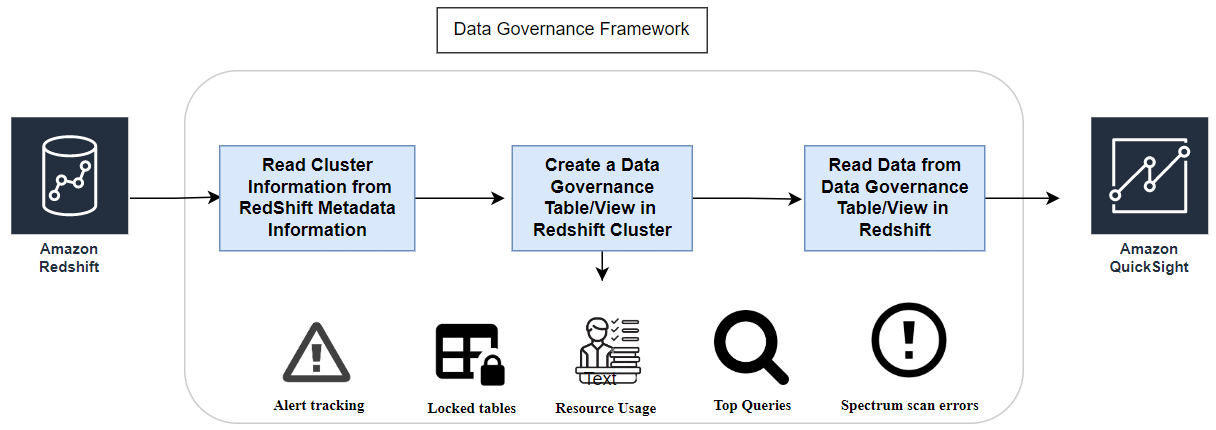
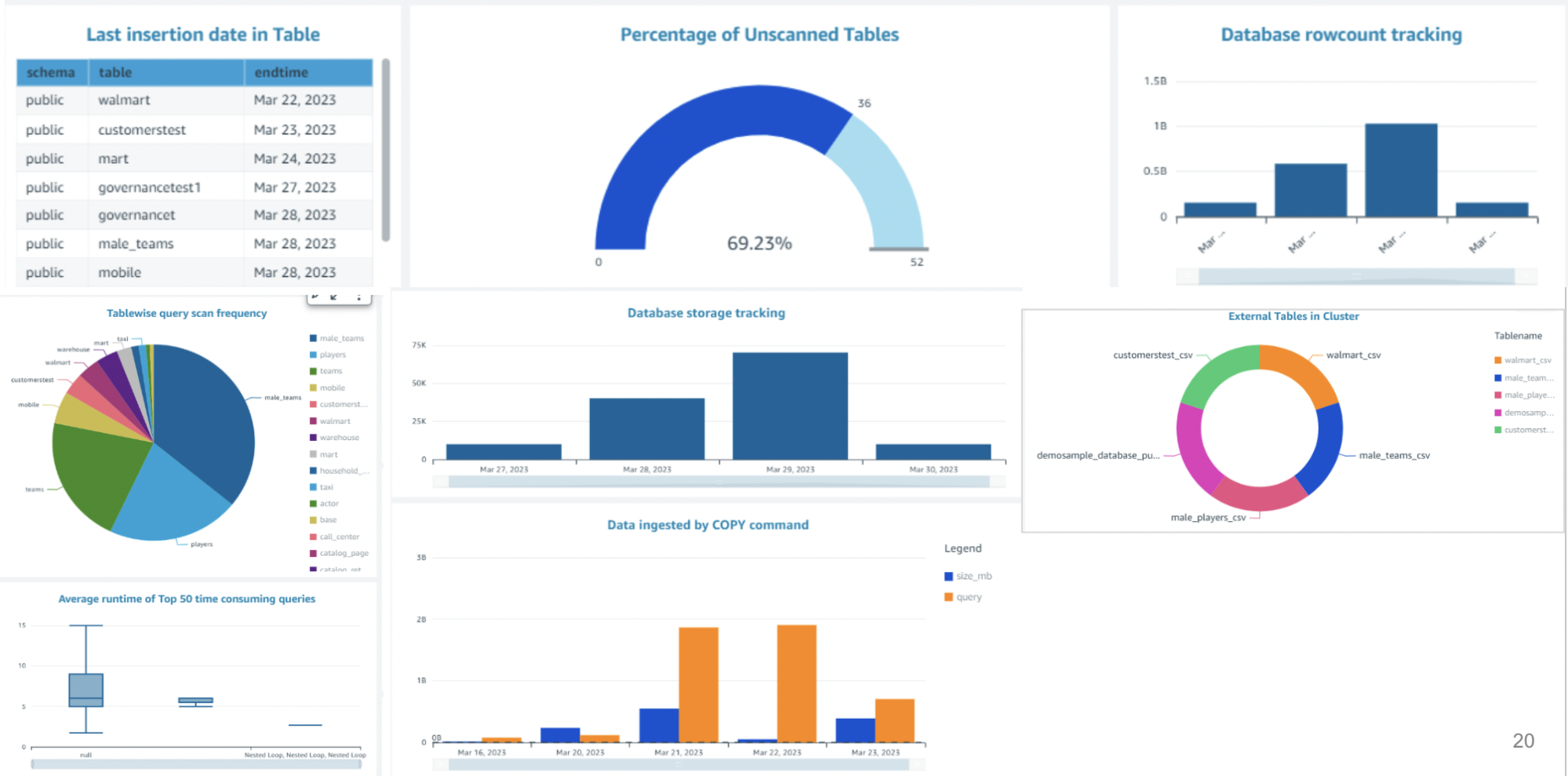
How does this work?
Amazon RedShift Data Governance accelerator will help in governance of Amazon Redshift clusters. In Amazon Redshift, there are various system level tables/views which capture relevant metadata information of the cluster which we can leverage to create a governance framework. This will aid users by preventing them from creating data swamp and govern the data warehouse in an efficient manner.